FIFA世界杯官方合作指定网站 VAST+清华提议3D生成新范式, 空间智能密度戒指把算力花在刀刃上


若是把面前最热点的几条 3D 生成时间线放在一谈看,你会发现它们正在碰到一个很像的问题。
作念 3D AIGC 的东谈主会发现,模子如故越来越会 “生成一个东西”,但生成收尾的复杂度很固定,不够纯真;作念图形学和渲染的东谈主会更介意,3D 暗示到底能不可把有限的策动预算用在最环节的所在;作念游戏、XR 和交互内容的东谈主则会不时追问,合并个 3D 财富能不可既有高质地版块,也有轻量版块,而不是每次都再行作念一套。
这些问题背后,其实都指向合并个中枢矛盾:
今天好多 3D 生成步伐,固然能生成 3D 收尾,但还不够 “会分拨资源”。
以 3D 高斯暗示为例,那儿高斯球应该密少许,那儿不错稀少少许;那儿值得放更多暗示智商,那儿只需要一个和粗陋近似,好多步伐其实并莫得真确学会。现存步伐更像是在用一种固定模板生成 3D,而不是凭据物体本人的结构复杂度,自适合地决定 “该放些许高斯、放在那儿”。
SIGGRAPH 2026 论文《Generative 3D Gaussians with Learned Density Control》,想惩处的恰是这个问题。

论文:《Generative 3D Gaussians with Learned Density Control》
论文衔接:https://arxiv.org/abs/2605.16355
这篇使命来自 VAST 和清华大学,提议了一种新的 3D 暗示方式 Density-Sampled Gaussians(DeG)。它的指标不是浅显生成固定数目的 3D 高斯球,而是让模子我方学会一种 “高斯球采样政策”: 在复杂区域多放高斯球,在浅显区域少放高斯球,何况这种政策还能径直从渲染纰谬里学出来。
这件事听起来像是工程优化,但其实相当环节。因为它决定了 3D 生成收尾最终是一个 “看起来还行但很珍惜的静态输出”,如故一个真确不错按预算伸缩、按需求部署、按场景适配的 3D 暗示。
畴前一段时分,3D 高斯之是以火,一个很病笃的原因是它在画质和着力之间找到了很好的均衡。它毋庸像传统网格那样依赖复杂拓扑,也能渲染出高质地收尾。3D 高斯的优化过程有一个环节优点,也恰恰亦然它最难被 Diffusion 等生成式模子收受的部分,便是空间密度戒指 (density control)。
在 3D 高斯优化过程里,优化算法会不断作念 密集化 (densification) 和 稀少化 (pruning)。浅显剖判便是:
若是某个局部没拟合好,就往那里 “补” 更多高斯;若是某些高斯孝敬不大,就把它们删掉。
这套机制很有用,因为现实里的 3D 物体本来就不是均匀复杂的。边缘、薄结构、纹理剧烈变化的区域,需要更多暗示智商;而大块平整、变化不大的区域,其实没必要堆太多高斯球。
问题在于,这种 “补点和删点” 的历程本色上是翻脸的、启发式的、不可微分的。
这个过程对单个物体的拟合很有用,但不可为微分的特质对一个作念前馈式生成、从图像径直展望 3D 高斯 的模子来说,就很难径直搬过来套用。于是好多现存步伐退而求其次,采选固定结构:
有的步伐把高斯绑在体素网格上 (GaussianCube);
有的步伐给每个 voxel 分拨固定数目的高斯 (TRELLIS.1);
有的步伐给每个 2D 图像的像素展望固定数目的高斯 (LGM)。
这么作念天然更容易教诲,但代价也很彰着:失去了 3D 高斯最稀少的纯真性。
DeG 的中枢想路,便是把 “高斯球中心在哪” 这件事,从一个固定归来问题,改写成一个从概率密度里采样的问题。
换句话说,模子不再呆板地输出一组固定坐标,而是先学一个 3D 空间里的概率密度分散。这个分散不错剖判为:
哪些位置更值得放高斯,哪些位置没那么病笃,即杀青了某种“空间智能密度戒指”。
在推理时,模子从这个分散里径直采样出一批高斯球,构成最终的 3D 高斯财富。
这么一来,扫数暗示坐窝赢得了两个相当实用的智商。
第一个智商,是纵脱数目采样。
因为模子学到的是 “分散”,而不是 “固定长度输出”,是以在推理时不错按试验需求采样不同数目的高斯球。想作念迁移端、及时预览能够低本钱传输,不错少采一些;想作念高保真渲染、离线展示能够更复杂场景,不错多采一些。
也便是说,这不是 “每种远离率都要再行训一个模子”,而是合并个模子、合并个暗示,凭据预算径直调采样数。
探究到 3D 高斯的渲染本钱并不低,纯果然高斯球数目对试验部署相当病笃。因为好多左右要的不是王人备最强画质,而是 “在现时开拓和现时时延预算下,拿到最适宜的 3D 财富”。

第二个智商,滚球app中国官网下载入口长短均匀采样。
DeG 并不是在扫数空间里平均撒点,而是会在模子教诲时凭据渲染重构亏损,把更多采样预算放到真确复杂的区域。比如薄的结构、明锐边缘、局部几何变化大、纹理更明锐的区域,都不错天然得到更高密度;而在平坦、顺次、变化较小的区域,则不错少放一些高斯。

这意味着,模子初始真确具备一种“那儿病笃就把容量放那儿”的智商。
而这,亦然本文最挑升想的算法问题所在:
这个空间上的智能密度戒指政策,到底若何学?
好多东谈主第一次看到这里会以为,既然临了有渲染亏损,那就径直反向传播不就行了?
但真确的难点在于,高斯球的位置是采样出来的。采样本人不是一个庸俗的连气儿映射,因此渲染纰谬没法像通例神经网罗那样,顺滑地一齐反传回 “空间密度分散”。
也便是说,模子固然知谈渲染收尾那儿错了,却拦阻易知谈:
到底应该提高哪些区域被采样到的概率,又该裁减哪些区域的概率。
这篇论文的环节冲破,便是给这个问题构造了一个可教诲的梯度信号。作家把它称为渲染亏损孝敬梯度 (render loss contribution gradient),本色上是一种强化学习政策,不错剖判为一种面向高斯采样的 policy gradient。
这个见识其实很直不雅。
假定现时咱们从密度分散里采样出了一批高斯球。面前,若是把其中某一个高斯球去掉,再行看渲染亏损会发生什么?
若是去掉它之后,渲染收尾彰着变差,证明这个高斯球很病笃,它如实帮模子把这个区域暗示好了。那么系统就应该耕作近似位置今后被采样到的概率。
反过来,若是去掉它险些没影响,甚而让收尾更好,那证明这类位置的采样价值不高,概率就不该那么大。
换成更白话的话,这个梯度在回话的问题其实便是:
“这一个被采到的高斯球,到底值不值得被采到?”
这便是一种相当典型的政策学习视角。采样位置像是在 “作念有蓄意”,渲染纰谬则提供 “赏罚信号”。对裁减纰谬有匡助的位置,2026世界杯官网入口就奖励;匡助不大的位置,就少奖励甚而处分。
从数学上看,这套想路和 policy gradient 是一致的。作家把它进一步写成了 difference reward 的形状,也便是比较 “有这个高斯球” 和 “莫得这个高斯球” 时,渲染亏损到底收支些许。这个差值,碰劲形容了该高斯球的边缘孝敬。
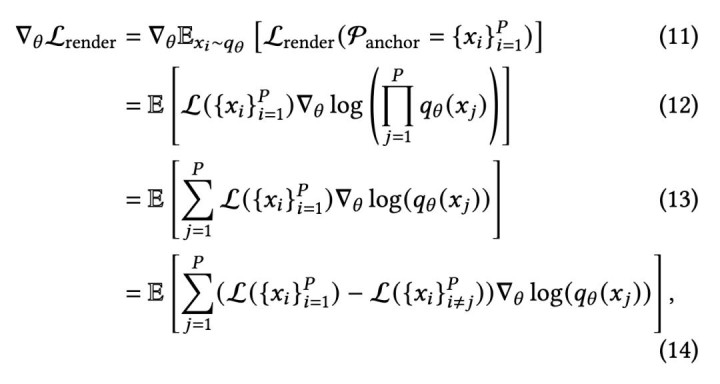
更病笃的是,这里不仅仅一个直观上说得通的评释,而是有明确的正确性依据。论文径直从 “渲染亏损盼望值” 启航,策动了它对密度分散参数的梯度大小,临了得到的便是这里真确用来优化的梯度信号,也便是渲染亏损孝敬梯度。换句话说,作家并不是凭训戒想象了一个看起来合理的教诲妙技,而是在用梯度下落的方式,径直优化高斯该如何分散、如何采样;这和传统高斯里基于东谈主工顺次的剪枝、密化,是收尾近似、但想路完全不同的一条路。
若是严格去算每个高斯球的 leave-one-out 孝敬,代价会相当高,因为看起来像是要把每个高斯都单独删掉,再再行渲染一遍。
接下来的问题就酿成了:这个指标固然界说得很领路,但如何才智把它高效算出来?作家针对 L1 渲染亏损给出了一种极端精准、同期又很高效的策动主义。
浅显来说,关于 L1 渲染项,渲染器在平方渲染过程中其实如故拿到了几个环节数值,只需要作念少许特地策动,就能得到咱们需要的孝敬值,而不必反复删掉高斯再重渲染。具体策动过程不错径直阅读论文中的伪代码。
这么一来,正本依赖顺次的密集化 / 稀少化过程,就被改写成了一个可微、可学习、可批量教诲的空间密度优化过程。这篇使命第一次把 3D 高斯的密度戒指,真确杀青成了一个端到端优化的问题。
在以往的高斯步伐里,密度戒指更多是靠东谈主工顺次驱动的,比如什么时候分裂、什么时候删点、阈值若何设、什么区域算 “该加密” 或 “该剪枝”,本色上都如故启发式想象。DeG 的不同之处在于,它不再依赖这些手工界说的顺次去变嫌高斯数目,而是让 “那儿该多采、那儿该少采” 径直由渲染纰谬反向决定。
若是从左右视角看,这套步伐的价值更能直不雅体现。
领先,它让 3D 财富真确具备了按预算伸缩的智商。
以前好多步伐一朝生成完成,输出范围基本就固定了。你想要更轻量,往往只可后处理压缩;你想要更高质地,也相情愿味着再行教诲、再行拟合,能够一初始就背上很重的暗示本钱。
而在 DeG 里,模子输出的是一个 “可采样的密度”。这意味着合并个对象,不错天然得到不同范围的高斯版块。对迁移端、及时交互、在线预览来说,不错采样更少、更轻的版块;对影视级展示、数字藏品、离线精修等任务,则不错径直提高采样预算,得到更密、更高超的版块。
其次,它让 3D 暗示真确初始剖判局部复杂度。
好多固定结构步伐的问题不在于它们不可生成高斯,而在于它们不知谈哪些所在更值得花预算。收尾往往是浅显所在堆得太多,复杂所在反而不够。DeG 的非均匀采样恰好反过来,把容量更荟萃地放在细节、规模、薄结构和高纰谬区域上。这件事在低预算场景里尤其病笃。因为当总高斯数目有限时,“若何分拨” 比 “总量些许” 更环节。论文实验里也暴露,这种空间智能密度戒指带来的收益,在少数目高斯的区间尤其彰着。换句话说,预算越紧,这种步伐越体现价值。
再进一步看,这种智商关于好多场景都很环节:
对游戏和 XR 来说,它意味着合并个生成模子更容易适配不同开拓品级和及时性能拘谨。
对 3D 内容平台来说,它意味着财富不错更天然地提供多种质地档位,而不是为每个档位单独制作,杀青近似 LoD 的成果。
澳门十大信誉网2026世界杯(中国)官网对 AIGC 使命流来说,它意味着生成系统不仅仅 “给一个收尾”,而是给出一个更可调、更可部署的暗示。
对机器东谈主仿真、数字孪生和交互式 AI 环境来说,它则意味着有限资源不错优先用在真确影响几何感知和渲染质地的部分。
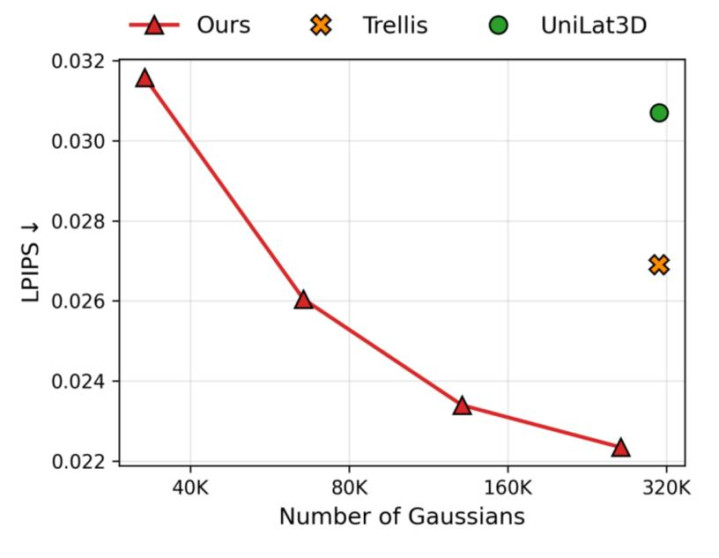
论文里也给出了很有代表性的收尾。作为一种单图到 3D 的生成框架,DeG 在重建和生成上都取得了很强的发达。在接近的高斯预算下,它比拟 TRELLIS、UniLat3D 等代表性步伐取得了更好的视觉质地;而若是只看 “达到左近视觉质地要用些许高斯”,DeG 能显耀减少所需高斯数目。论文中还提到,在某些场景下,它达到与 TRELLIS 极端的视觉质地时,所需高斯数目不到后者的一半。

从更长的时间线索看,这篇使命辅导了一个很病笃的标的:
3D 生成模子能不可不单隆重 “生成出来”,还隆重决定 “资源该若何分拨”?
这看上去像一个底层问题,但它径直决定了 3D AIGC 能不可从 “实验室成果” 走向 “试验可用”。的确宇宙的部署从来不是无尽预算的,真确有价值的模子,不仅仅会生成,还要知谈在预算有限的情况下,什么最值得被保留。
DeG 的真谛,就在于把这种 “保留什么、强调什么、稀少什么” 的智商,第一次以可学习、可优化的方式交给模子我方去决定。它让 3D 暗示不再是固定长度、固定密度的静态输出,而酿成一种能按需要调密度、调本钱、调质地的抒发。
若是再往前想一步,这篇使命还会逼着咱们再行想考一个很基础的问题:一个物体的高模和低模,到底应该被作为两个不同的东西,如故合并个物体在不同资源拘谨下的两种现象?
在传统历程里,咱们频繁把它们当成两份不同财富,是以建模、简化、LOD 制作和部署被拆成了几条链路。但 DeG 辅导了一种更天然的剖判:物体本人莫得变,变化的仅仅咱们好意思瞻念为它分拨些许暗示智商和渲染预算。
若是这个视角建立,那么改日的 3D 生成模子学到的就不仅仅 “长什么样”,还包括 “在什么条目下,该以什么密度、什么本钱被呈现出来”。当时,高模、低模、迁移端版块,也许都不再是彼此割裂的几份财富,而会酿成合并个对象在不同场景下的连气儿现象。
从这个真谛上说FIFA世界杯官方合作指定网站,DeG 固然作念的是 3D 高斯,但它真确挑升想的所在,也许在于它提醒咱们:改日的 3D 内容不一定是一份静态谜底,而更可能是一种会跟着开拓、任务和预算不断调停的“活暗示”。